
Modello Italia è il large language model (LLM) sviluppato dalla società informatica iGenius, fondata da Uljan Sharka, e addestrato sul supercomputer Leonardo, gestito dal Consorzio Interuniversitario Cineca, su un dataset per il 90% composto da informazioni in lingua italiana.
Solo due giorni fa iGenius è diventata il primo unicorno italiano nell’IA, secondo la medesima società che dopo un altro aumento di capitale ha visto l’ingresso del fondo di Angelo Moratti e di Eurizon del gruppo Intesa Sanpaolo.
Ma Modello Italia non è l’unico LLM a essere stato addestrato su dati italiani. In ambito privato c’è anche Fastweb, mentre a livello universitario ci sono vari progetti, tra cui LLaMAntino dell’Università degli Studi di Bari, Cerbero dell’ateneo di Pisa e Fauno, Camoscio, Dante e Minerva a La Sapienza di Roma.
E proprio l’università romana ha convertito, in una versione non ufficiale, il checkpoint di Modello Italia e lo ha reso disponibile sulla piattaforma di Hugging Face dove è possibile mettere a confronto diversi LLM.
L’ANALISI DI MODELLO ITALIA DA PARTE DELLA SAPIENZA
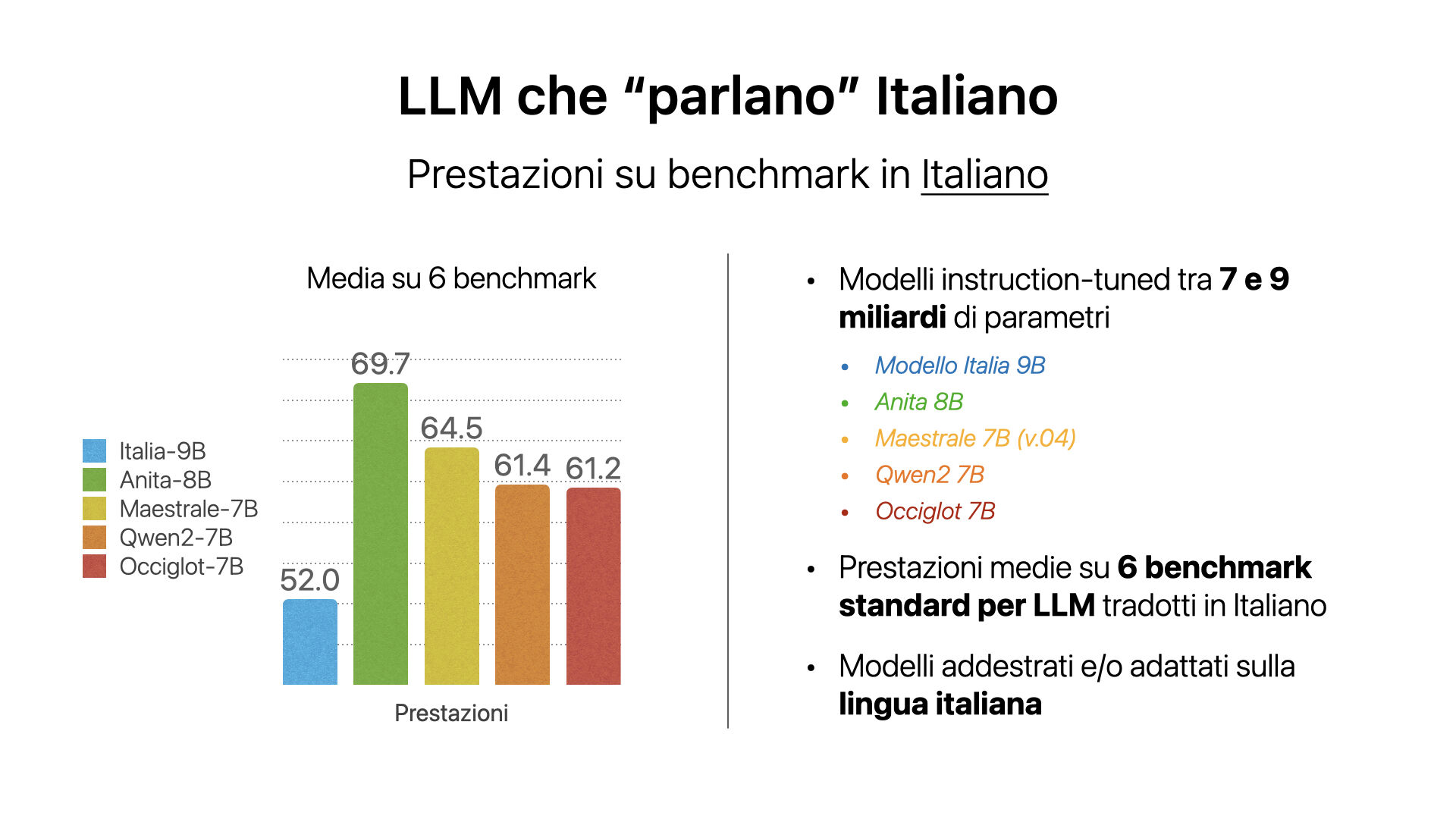
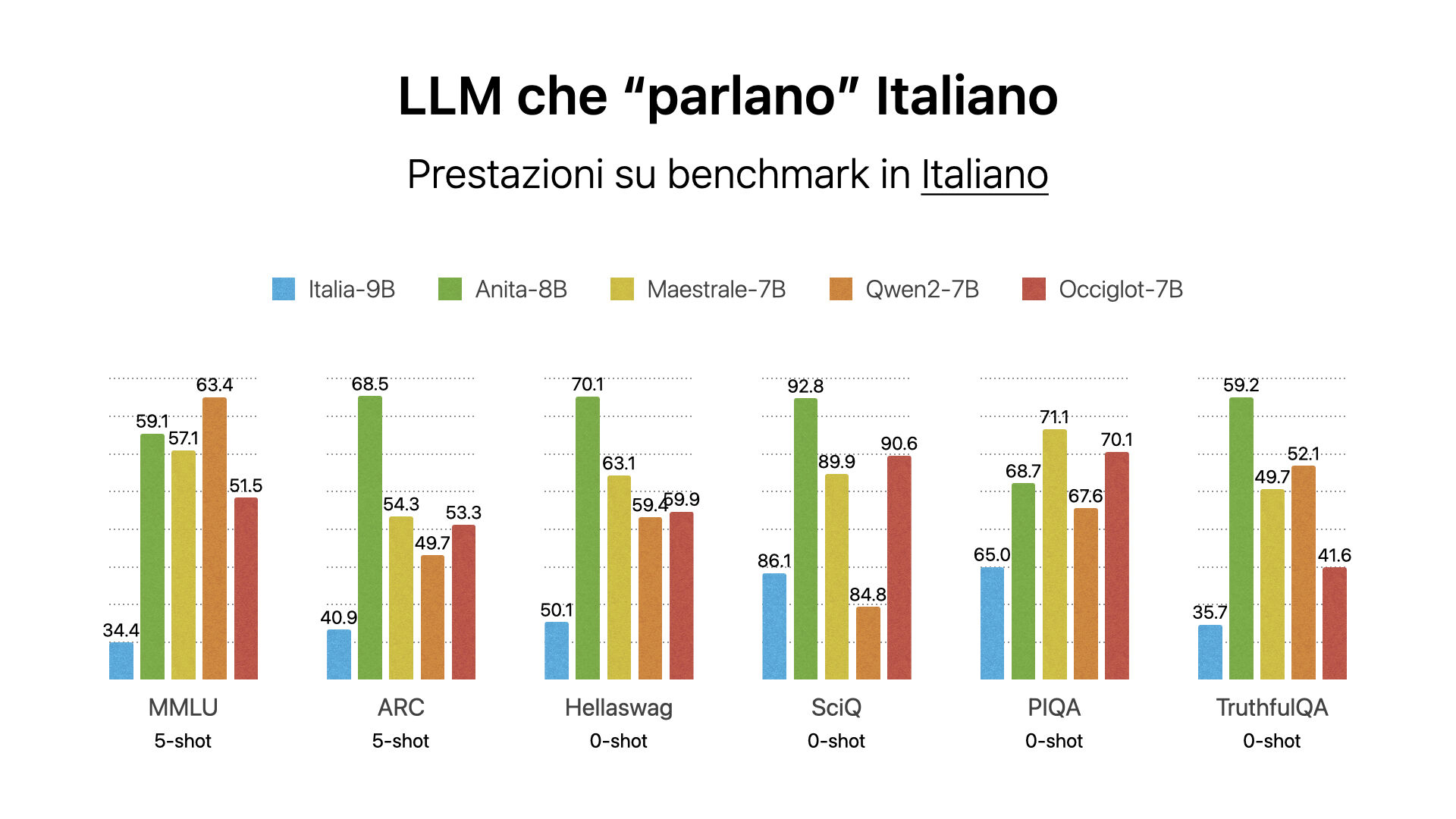
Il gruppo di ricerca della Sapienza ha quindi condotto un’analisi preliminare delle capacità di Modello Italia (Italia-9B) su 6 benchmark standard per LLM tradotti in italiano, che fanno parte di una nuova evaluation suite che verrà rilasciata a breve in maniera open-source per promuovere la riproducibilità e la trasparenza degli esperimenti.
“Nella nostra analisi – spiegano i ricercatori -, abbiamo comparato Modello Italia con altri 4 modelli di dimensioni simili (da 7B a 8B) addestrati o adattati sulla lingua italiana”.
In particolare, i modelli messi a confronto con Italia 9B sono Anita 8B, Maestrale 7B, Qwen2-7B, Occiglot 7B.
Come chiarito dal gruppo, i modelli addestrati da zero sulla lingua italiana sono Italia 9B e Qwen2. Mentre Anita da LLama3, Maestrale da Mistral e Occiglot da Mistral sono modelli adattati alla lingua italiana tramite fine-tuning.
LA VALUTAZIONE
Seppur premettendo che l’analisi potrebbe non rispecchiare le prestazioni del modello originale, in quanto è stata utilizzata la conversione non ufficiale del modello rilasciato da iGenius, secondo i ricercatori le prestazioni di Modello Italia rispetto ai 6 benchmark presi in considerazione risultano inferiori a tutti gli altri, con Anita 9B che invece batte tutti.
Anche nella classifica degli LLM che parlano italiano, stilata da Hugging Face, risulta molto indietro rispetto a tanti altri.
LA RISPOSTA DI IGENIUS
Al post su LinkedIn pubblicato dalla Sapienza con i risultati dell’analisi ha risposto Nicolas Pantaleo, product management lead presso iGenius che, oltre a ringraziare per aver portato Italia 9B nella community di Hugging Face, ha voluto precisare che nella conversione del modello “hanno notato molte differenze che influiscono negativamente sulle performance finali”.
Pantaleo, quindi, ha garantito che “presto Italia sarà disponibile anche sul profilo Hugging Face ufficiale di iGenius”, dove saranno forniti ulteriori dettagli tecnici sul modello.







