La Stanford University ha appena pubblicato il suo AI index report dedicato a fare il punto sullo stato attuale della disciplina.
Per sua natura, questo è un riepilogo di dati già noti, ma è interessante trovare una prospettiva autorevole e unificata sullo stato attuale dell’impresa.
Il briefing iniziale si apre così:
“Le prestazioni dell’intelligenza artificiale nei benchmark più impegnativi continuano a migliorare.
Nel 2023, i ricercatori hanno introdotto nuovi benchmark (MMMU, GPQA e SWE-bench) per testare i limiti dei sistemi avanzati di intelligenza artificiale. Solo un anno dopo, le prestazioni sono aumentate drasticamente (…)
Al di là dei benchmark, i sistemi di intelligenza artificiale hanno fatto grandi passi avanti nella generazione di video di alta qualità e, in alcuni contesti, i modelli linguistici addirittura hanno ottenuto risultati migliori degli esseri umani nelle attività di programmazione con budget di tempo limitati.”
Questo punto viene illustrato con un grafico eloquente a pagina 93, una versione aggiornata e più “ufficiale” di quello che nel mio libro Sovrumano (Il Mulino) chiamo “la pagella”: ovvero il voto ottenuto dalle migliori AI in varie “materie”, ciascuna rappresentata da un diverso esame (chiamato “benchmark” nel gergo tecnico).
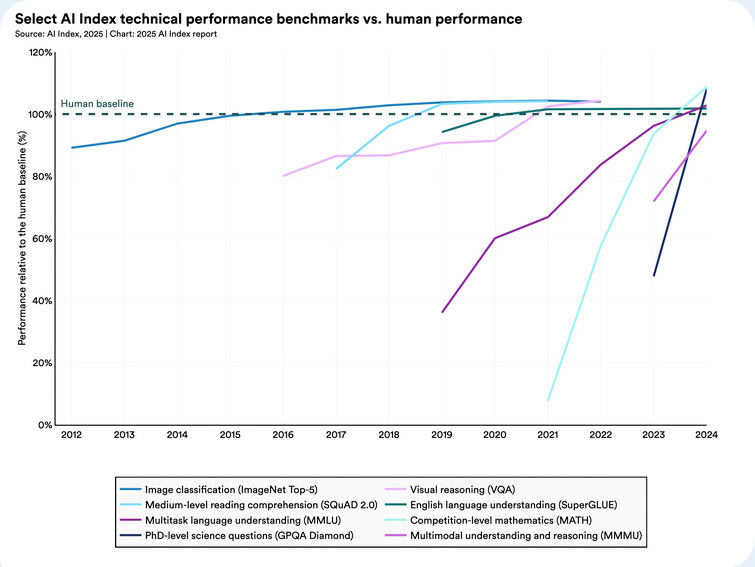
Ecco qui i risultati: la linea tratteggiata al 100% rappresenta il livello umano, per ciascun compito, le linee colorate rappresentano i punteggi conseguiti negli ultimi 12 anni dalle AI, ogni colore corrisponde a un test diverso.
I punteggi al di sopra del 100 sono punteggi che superano le prestazioni umane. Non è questo il posto per illustrare con degli esempi le varie domande che formano ciascun esame, ma potete trovarle nel libro Sovrumano.
Di particolare importanza, in questo grafico, è la linea chiamata GPQA Diamond, che contiene domande in materie scientifiche a livello di PhD, dove fino a due anni fa l’AI aveva prestazioni inferiori a quelle degli esperti umani.
Lo stesso vale per il test MATH (che contiene domande tratte da competizioni matematiche). Nell’ultimo anno, questi due esami hanno superato la linea tratteggiata, quella delle prestazioni umane, e con questo si intendono gli esperti umani perché non credo che io potrei rispondere a domande di biochimica a quel livello. In altre materie il sorpasso era già avvenuto negli anni precedenti.
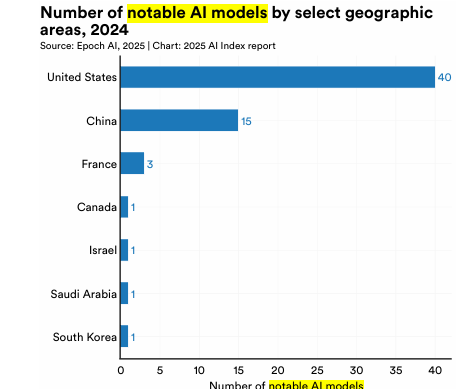
Ci sono anche altri punti importanti, in questo report, e consiglio di leggerli. Uno in particolare va preso seriamente, in Italia, ed è a pagina 43.
Ci sono solo tre modelli “degni di nota” (notable) in Europa, e sono tutti in Francia. “Degno di nota” è così definito:
“Il termine “modelli di apprendimento automatico degni di nota” designa modelli particolarmente influenti all’interno dell’ecosistema dell’intelligenza artificiale/apprendimento automatico.”
Questo il testo originale:
“Per illustrare l’evoluzione del panorama geopolitico dell’IA, l’AI Index mostra il paese di origine dei modelli più significativi. La figura mostra il numero totale di modelli di intelligenza artificiale degni di nota attribuiti all’ubicazione delle istituzioni affiliate dei ricercatori.
Nel 2024, gli Stati Uniti erano in testa con 40 modelli di intelligenza artificiale degni di nota, seguiti dalla Cina con 15 e dalla Francia con tre.”
Per una lettura più approfondita, cliccate qui: Artificial Intelligence Index Report 2025.
(Estratto dalla newsletter Appunti di Stefano Feltri)






