
La fonte di una notizia è tutto. Per i giornalisti ma, in teoria, anche per i lettori. Tuttavia, l’utilizzo sempre più diffuso dei chatbot basati sull’IA o le stesse ricerche su Google, ormai precedute dalle risposte di AI Overview, stanno rivoluzionando questo assunto. E, quindi, da dove arriva quello che ci propina l’intelligenza artificiale?
REDDIT DOMINA I CONTENUTI DELL’IA
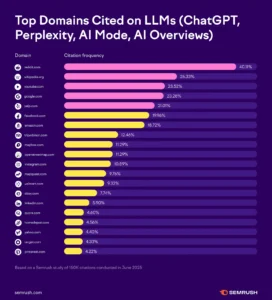
Secondo i dati Semrush di agosto 2025, basati su 150.000 citazioni da 5.000 parole chiave selezionate casualmente, il vincitore indiscusso è Reddit.
I modelli di intelligenza artificiale (LLM) attingono infatti per ben il 40,1% dal sito web di social news e aggregazione di contenuti, dove gli utenti registrati possono pubblicare link, testo, immagini e video. A votare i contenuti e quindi ad attribuirgli visibilità all’interno della piattaforma sono sempre gli utenti.
Ma questa modalità di indicizzazione delle informazioni espone a dei rischi riguardo alla qualità delle informazioni. Come ha scritto Wired, “la quasi ventennale storia di Reddit è un’altalena caratterizzata da scandali legati a contenuti inappropriati, bruschi cambi di leadership e rivolte degli utenti”. Reddit, infatti, a differenza di Wikipedia, che si basa su meccanismi di controllo e revisione, offre contenuti eterogenei, con livelli di accuratezza e autorevolezza molto variabili.
WIKIPEDIA, YOUTUBE E GOOGLE
Solo dopo Reddit figurano i più tradizionali Wikipedia, YouTube e Google. Wikipedia si posiziona al secondo posto con il 26,3% delle citazioni nei contenuti generati dall’IA, seguito quasi alla pari da YouTube (23,5%) e Google (23,3%).
Come osserva Prima Online, Wikipedia viene preferita dai modelli IA per i suoi contenuti strutturati e verificabili. L’enciclopedia ha però sollevato preoccupazioni sull’uso dei suoi dati senza attribuzione, che potrebbe ridurre traffico e collaborazione degli utenti, generando un paradosso: l’IA dipende da Wikipedia, ma può indebolirne il modello partecipativo.
YouTube, invece, è apprezzata per la varietà di contenuti multimediali utili a risposte più dinamiche, mentre il risultato di Google mostra che il motore di ricerca più usato e per come lo conosciamo ha iniziato a perdere centralità a favore degli strumenti IA integrati.
Tanto che lo scorso maggio, ha introdotto la modalità IA, sostituendo il classico modello dei “dieci link blu” con risposte sintetiche generate dall’intelligenza artificiale. Un’innovazione che sta ridefinendo il flusso del traffico online, con impatti diretti sui modelli economici alla base del web. Inoltre, va ricordato l’accordo da 60 milioni di dollari all’anno con Reddit per avere accesso diretto ai dati del forum per il training degli algoritmi.
LE ALTRE PIATTAFORME
La classifica di Semrush prosegue poi con una serie di piattaforme che, pur avendo un impatto minore, mantengono un ruolo rilevante. Yelp (21%), Facebook (20%), Amazon (18,7%) e TripAdvisor (12,5%) forniscono contributi specifici legati a recensioni, interazioni sociali e commercio online. Anche i sistemi di mappatura come Mapbox e OpenStreetMap (11,3%) risultano utili, soprattutto per funzioni legate alla geolocalizzazione e alla visualizzazione di percorsi.
OGNI MODELLO HA LE SUE PREFERENZE
Dalla ricerca emerge inoltre che ciascun modello IA ha una predilezione particolare per una di queste fonti da cui attinge. Reddit, per esempio, è la fonte più citata da ChatGPT, Perplexity AI e Google AI Mode, confermandosi centrale per i modelli che privilegiano contenuti generati dagli utenti.
Al contrario, piattaforme come YouTube assumono maggiore importanza per i sistemi che puntano sulla componente visiva e multimodale, integrando video, immagini e audio nelle risposte.
QUANTO POSSIAMO FIDARCI DELL’IA?
Uno studio condotto dalla Columbia Journalism Review e riportato dal Corriere ha evidenziato gravi carenze nei motori di ricerca basati su intelligenza artificiale. Testando otto chatbot, tra cui ChatGPT, Gemini e Perplexity, le giornaliste hanno scoperto che oltre il 60% delle risposte era errato, spesso fornito con eccessiva sicurezza e senza ammettere incertezze o limiti. ChatGPT, ad esempio, ha sbagliato 134 risposte su 200, riconoscendo i propri limiti solo in 15 casi.
I modelli premium (come Perplexity Pro e Grok 3), pur fornendo più risposte corrette rispetto alle versioni gratuite, hanno mostrato tassi di errore ancora più alti, proprio perché tendevano a rispondere sempre con sicurezza, anche quando sbagliavano.
Ma un problema ancora più serio riguarda i link: molti chatbot hanno fornito URL inventati o errati. Grok 3, per esempio, ha indirizzato verso pagine inesistenti nel 77% dei casi. Anche quando l’articolo veniva identificato correttamente, spesso il link non portava alla fonte originale.
Questi limiti non solo mettono a rischio l’affidabilità dell’informazione, ma penalizzano anche le testate giornalistiche perché i chatbot rispondono direttamente all’utente senza generare traffico verso i siti, compromettendo i ricavi pubblicitari e la sostenibilità economica del giornalismo online.






